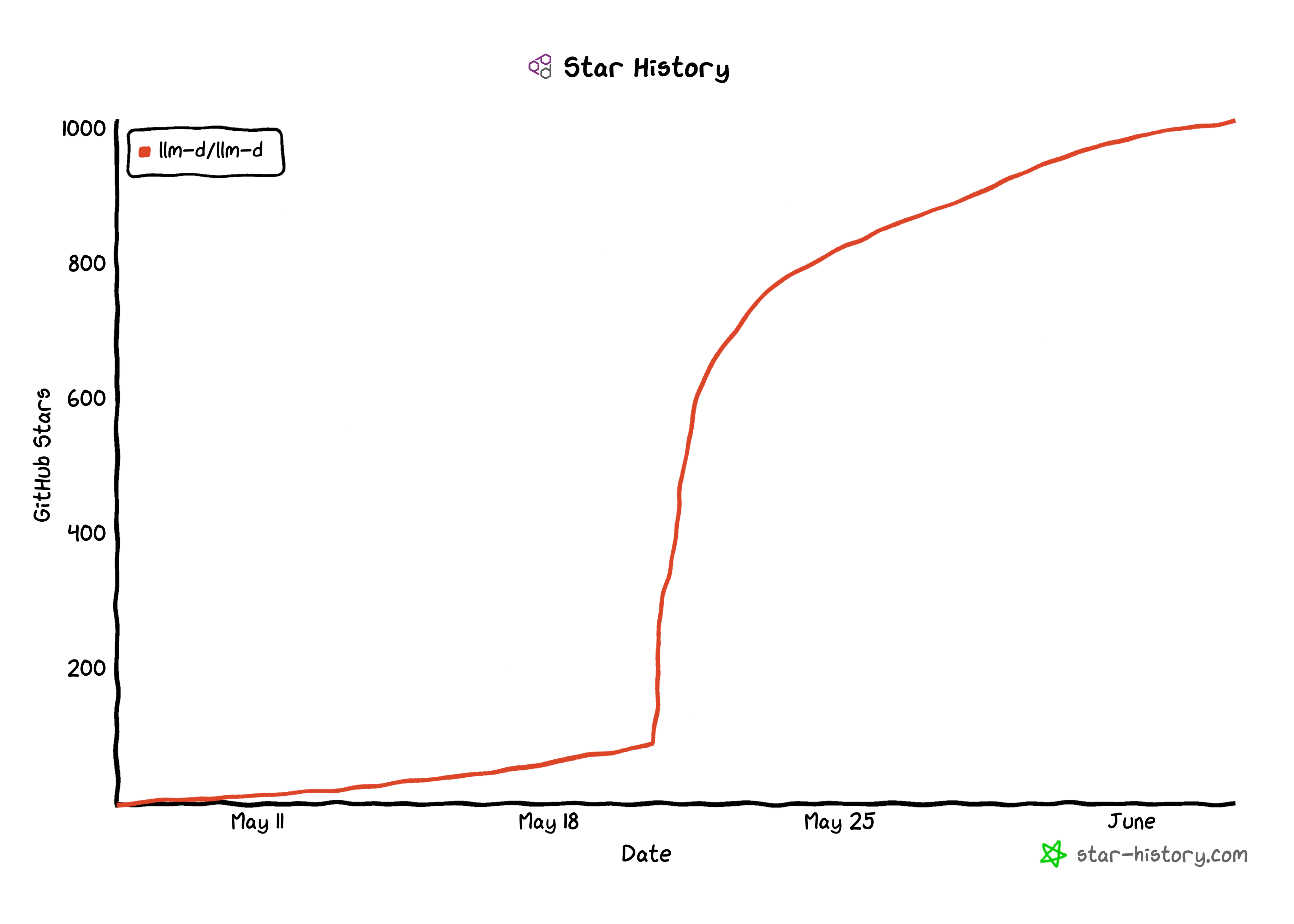
Mastering KV-Cache-Aware Routing with llm-d
· 9 min read

Introduction
In the era of large-scale AI inference, ensuring efficiency across distributed environments is no longer optional—it's a necessity. As workloads grow, so does the need for smarter scheduling and memory reuse strategies. Enter llm-d, a Kubernetes-native framework for scalable, intelligent LLM inference. One of its most powerful capabilities is KV-cache-aware routing, which reduces latency and improves throughput by directing requests to pods that already hold relevant context in GPU memory.
Version Note
This blog post is written for llm-d v0.2.0. For detailed release information and installation instructions, see the v0.2.0 release notes.
In this blog post, we'll cover:
- What KV-cache-aware routing is and why it matters
- How llm-d implements this feature with EPPs, Redis, and NIXL
- The critical Kubernetes YAML assets that make it work
- A test case showing our latest 87.4% cache hit rate
- Where to go to learn more and get started